Vanhan viisauden mukaan pelitekoälyn tehtävänä on hävitä viihdyttävästi. Viime aikoina sen tehtävänä on ollut voittaa.
Tekoälykehityksen yksi kiinnostavimmista projekteista on Deepmindin Alpha-projekti. Shakkia monimutkaisempi Go oli ihmisälyn valtakuntaa pitkään, mutta oppivaan tekoälyyn perustuva AlphaGo kukisti maailman parhaat go-pelaajat vuonna 2016.
AlphaGon pohjalta kehitetty AlphaZero niittasi maailman parhaat shakki- ja go-tekoälyohjelmat, vaikka Zero-versiolle ei ollut alussa kerrottu kuin pelien säännöt. Neuroverkko oli opetellut edeltäjiään paremmaksi vuodessa.
Vuonna 2019 AlphaZeroon perustuva MuZero-tekoäly alkoi opetella videopelien pelaamista. Videopelit ovat neuroverkon kannalta haaste, koska neuroverkot soveltuvat parhaiten tilanteisiin, joissa analysoitavaa dataa on valtavasti. Peleissä on harvoin kaikki tieto käytössä, plus puuttuvan dataongelman lisäksi siirtoja ja mahdollisia vaihtoehtoja on valtavasti. Ihminen pystyy tekemään päätökset vastaavissa tilanteissa intuition ja kokemuksen varassa.
MuZeron kohdalla ongelma on tarkoituksella tehty vielä suuremmaksi, AlphaZerosta poiketen MuZero ei tiedä edes videopelien sääntöjä.
Raakaa dataa
MuZero ei ole Deepmindin ensimmäinen retki videopelimaailmaan. Ennen MuZeroa tutkijat kehittivät AlphaStar-tekoälyn 2016, joka erikoistui Starcraft 2:n pelaamiseen. Blizzard antoi tutkijoiden käyttöön huippupelaajien keskinäisten pelien datan, joiden pohjalta AlphaStar opetteli imitoimaan turnauspelejä.
AlphaStar laitettiin pelaamaan itseään vastaan 44 päiväksi. Tutkijoiden mukaa AlphaStar ehti siinä ajassa tahkota niin monta ottelua, että ihmiseltä samaan määrään pääseminen veisi noin 200 vuotta tauotonta pelaamista. Tekoälystä kehitettiin kolme eri versiota, jotka erikoistuivat zergin, protossin ja terranin pelaamiseen. Lisäksi käytössä oli vielä exploit-versio, jolla tutkijat yrittivät ohjata AlphaStaria löytämään omat puutteensa.
Lopputuloksena AlphaStar ylsi Starcraft 2:ssa Grandmaster-tasolle kaikilla kolmella rodulla, mutta ei pärjännyt sadan parhaan pelaajan kärjelle. Huippupelaajien mukaan AlphaStar pelasi hyvin, mutta ei täysin optimaalisesti. Lisäksi se ei osannut reagoida yllättäviin taktiikoihin. Esimerkiksi liki pelkkiin lentoyksiköihin keskittyminen riitti kukistamaan AlphaStarin, joka pelasi itse kuin turnauspeliä ja odotti standarditaktiikkaa myös vastustajalta.

Haluatko MuZeroon jäitä?
AlphaStarissa ohjelmoijat kertoivat tekoälylle, mikä Starcraftissa oli tavoitteena, mutta Atari 2600 -peleihin ”erikoistunut” MuZero on vielä mielenkiintoisempi. Tavoitteena on, että MuZero ymmärtäisi, mitä esimerkiksi Pac-Manissa pitää tehdä. Ainoa MuZeron pelistä saama data on kontrollit ja pikselit ruudulla.
Yksinkertaistettuna MuZero käyttää kolmen kysymyksen sapluunaa: Miten hyvä nykyinen sijainti on? Mikä on paras ratkaisu? Miten hyvä oli edellinen siirto? Sen sijaan, että MuZero yrittäisi mallintaa ympäröivän todellisuuden, ohjelma keskittyy tunnistamaan oleelliset asiat. Käytännössä se kokeilee ensin vain satunnaisia asioita pyörien paikallaan, mutta kun sitä tekee serverifarmin laskentateholla miljoonien pelikertojen verran, alkaa huomata muutoksia pikseleissä.
Testipenkkinä toimi Atari 2600 ja sen 57 klassista peliä. Valinta ei ole sattumaa, sillä kasaripelit ovat suhteellisen kevyitä emuloitavia ja standardoitu testipenkki antaa mahdollisuuden verrata oppivia neuroverkkoja toisiinsa. Osa peleistä on idealtaan ja grafiikaltaan niin eksoottisen muinaisia, että harva ihminenkään enää hahmottaa, mitä niissä olisi tarkoitus tehdä. Haluaisin nähdä nykylapsen suorituksen esimerkiksi Solariksessa, jossa hypätään sektorilta toiselle, optimoidaan bensankulutusta ja kukistetaan lippulaiva lisälöpön toivossa.
Atarin salat aukesivat vaivaisessa 12 tunnissa. MuZero päihittää testipenkin 57 Atari-pelissä peräti 51:ssä ihmispelaajan. Mielenkiintoista on, missä peleissä tekoäly ei pärjää. Muinaista seikkailupeliä Montezuma’s Revengeä MuZero ei hallitse ollenkaan, koska tavoite on alussa liian kaukainen. Pelissä pitäisi päästä kahden lukitun oven takana olevaan huoneeseen. Kentässä on neljä avainta ja kuusi ovea. Avaimet käyvät kaikki oviin. Eteenpäin päästäkseen pelissä pitää ohittaa kaksi ensimmäistä ovea, mutta MuZero ei löydä yhteyttä.
Jos aikoi käyttää avainpuzzlea tietoisen tekoälyn suojabunkkerinsa suunnittelussa, ongelma on valitettavasti jo ohitettu. Tutkijat kehittivät Agent57-tekoälyohjelman, joka hallitsee kaikki Atari 2600 -pelit. Ratkaisuna oli luoda tekoälylle uteliaisuus eli se pyrki tutkimaan laajemmin ja ensimmäistä havaitsemaansa muutosta pidemmälle. Agent57-tekoälyssä ohjelmoijat puuttuivat lopputulokseen, joten se ei vastannut MuZeron kehittäjien alkuperäistä tavoitetta.
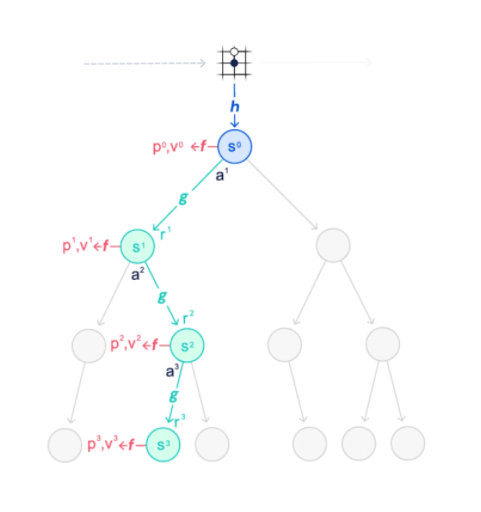
Edes Atari 2600 -peleissä ei ole kustannustehokasta kokeilla kaikkia siirtoja, joten MuZero ja Alpha-tekoälyt käyttävät niin sanottua ennakoivaa Monte Carlo -puuhakua. Tekniikassa ohjelma seuraa kuin puun oksistona kasvavaa erilaisten mahdollisten vaihtoehtojen määrää. Jo pelkässä Pac-Manissa eri ohjausliikkeiden vaihtoehdot kasvavat niin nopeasti niin suuriksi luvuiksi, että kaikkia mahdollisia vaihtoehtoja ei ole järkevää laskea.
MuZero ei tutki kaikkia vaihtoehtoja vaan antaa ratkaisuille edellisten pelien pohjalta ennustearvon, jonka perusteella se karsii vaihtoehtopuun oksista huonon lopputuloksen tuovat pois. Samalla ennustetta tarkennetaan koko ajan arvioimalla, miten hyvin veikkaus piti aiemmin kutinsa. Ennakoiva haku toimi lopulta niin tarkasti, että Pac-Mania MuZero pystyi pelaamaan sujuvasti, vaikka laskettavien siirtojen määrä rajattiin vain viiteen seuraavaan. Kentässä on useita kohtia, joissa viidellä siirrolla päätyy paikkaan, jossa ei voi enää väistää haamua. Toki siihen mennessä kokemusta oli kertynyt jo 20 miljardia pelikertaa.
MuZero on vain välivaihe. Deepmindin tavoitteena on kehittää yleiskäyttöinen algoritmi, joka osaa luoda itse ympäristön selittävän mallin ja hyödyntää malliaan parhaan toimintatavan valinnassa, vaikka kaikki data ei olisi käytössä.
Opi omista virheistä
Toinen kiinnostava puutteellisen tiedon varassa ratkaisuja tekevä tekoäly on Carnegie Mellon -yliopiston pokeritekoäly, jonka kehityksessä mukana on myös suomalainen tietotekniikan professori Tuomas Sandholm. Vuonna 2017 käydyssä The Brains vs Artificial Intelligence -turnauksessa Libratus-tekoäly voitti kaikki ihmispelaajat. No limit texas hold’emia pelattiin yksi vastaan yksi -tyylillä 20 päivää putkeen ja päivittäin peräti 11 tunnin ajan. Ei ihme, että ihmismieli väsyi ja hävisi jyystön.
Vuonna 2019 saman tekoälyn kehitetty versio Pluribus voitti kuuden pelaajan pöydässä kaikki, muun muassa huippupelaajana pidetyn Linus Loeligerin. Turnauksessa pelattiin kahdella eri tyylillä. Viisi ihmistä yhden botin pöydässä ja viisi bottia yhden ihmisen kanssa. Botti voitti ihmiset, vaikka pelejä tuli nyt ”vain” 10 000 ihmisiä vastaan.
Tekoälyn kannalta pokeri on vaikea hallittava, koska kaikki tieto ei ole pelaajien käytössä. Vastustajan kortteja ei tiedetä, joten todennäköisyydet voittaakseen pelaajan pitää pystyä hämäämään vastustajiaan, tunnistamaan bluffit ja vielä päättämään, kuinka paljon kuhunkin käteen kannattaa panostaa. Yllättäen ohjelma ei analysoinut vastustajiensa käyttäytymistä mitenkään, vaan perusti ratkaisunsa itseään vastaan käymiinsä miljooniin pokeripeleihin, joiden pohjalta päätökset tehtiin.
Ihmispelaajien kommenttien perusteella Pluribuksen vahvuus oli nimenomaan ennakoimattomuus. Pluribus käytti poikkeuksellisen suuria vetoja, mikä pakotti ihmiset miettimään, haluavatko he panostaa kortteihinsa aivan näin paljon. Ihmispelaajat eivät myöskään kortit nähtyään pystyneet analysoimaan, millä perusteella tekoäly oli vetonsa tehnyt, sillä korttivalikoima tuntui olevan tilanteissa hyvin laaja.
Pluribus myös erosi ihmispelaajista siinä, että se harrasti niin sanottua donkkaamista. Useimmiten ihmispelaajien pöydissä panoksen viimeksi maksanut siirtää korotusvastuun muille blindin jälkeisessä flopissa. Jos reagoikin korotuksella, donkkaa. Pluribus donkkasi kaksi kertaa useammin kuin ihmispelaajilla on tapana, mutta vain tilanteissa, joissa mukana oli vielä useita pelaajia.
Donkkia vältetään, mutta taustalla saattaa piillä samanlainen ihmismielen arviointivirhe kuin amerikkalaisessa jalkapallossa. Tilastojen mukaan jenkkifutiksessa kannattaisi aina yrittää pelata myös neljännellä yrityksellä, vaikka epäonnistuessa vastustaja saa hyökkäysvuoron. Intuitio kehottaa turvautumaan potkuun, jolla vastustaja saa todennäköisesti pallon, mutta kauempana omasta maalista. Riski tuntuu perinteisellä tyylillä pienemmältä, vaikka ei todellisuudessa ole.
Turnauksessa tilastot olivat Pluribuksen puolella. Tekoäly voitti keskimäärin 5 dollaria joka kädellä ja tahkosi rahaa noin 1 000 dollaria tunnissa viittä ihmispelaajaa vastaan. Ohjelma on vieläpä suhteellisen kevyt. Turnauksen aikana se käytti noin 150 dollarin edestä pilvipalveluiden laskentatehoa.
Tutkijoiden tavoitteena ei ole vuolla rahaa nettipokerissa vaan kehittää algoritmia ongelmien optimiratkaisuun puutteellisen informaation pohjalta. Käytännön sovelluksia voisi esimerkiksi löytyä sijoitusmaailmasta tai terveydenhuollosta.
Noob meatboy L2P!
Shakissa ihmiset eivät ole pärjänneet tekoälyä vastaan enää koko vuosituhannella, mutta yllättäen se ei ole osoittautunut lajille ongelmaksi vaan mahdollisuudeksi. Game Changer -kirja kertoo AlphaZerosta nimenomaan shakin näkökulmasta ja siitä, miten tekoäly kehittyi ja koneen pelityyli muovautui. Matthew Sadler ja Natasha Regan visioivat AlphaZeron kehityskulkuna yhteiskunnalliset ongelmat ratkaisevaan yleistekoälyyn, jota myös MuZero edustaa. Samalla tosin AlphaZeron tyyliä kuvataan aggressiiviseksi uhrauspeliksi, missä näkisin aika ilmeisen ristiriidan ihmiskunnan ongelmien ja itse ihmisten kannalta. Toki todellisuudessa optimiratkaisua etsivää tekoälyä suunnitellaan työkaluksi datan analysointiin eikä varsinaiseksi päätöksentekijäksi.
Tekoälyn voitosta alkoi shakin uusi kukoistuskausi, koska teoria kehittyi nopeammin kuin ihmismielen voimin oli aiemmin mahdollista. MuZeron tapaiset projektit avaavat samanlaisia mahdollisuuksia videopeleissä. Esimerkiksi pelin optimointi ja tasapainottaminen helpottuvat, jos pelaajia ei enää tarvitse käyttää koekaniineina. Jo nyt esimerkiksi kenttiä päästään testaamaan tekoälyboteilla, joiden keräämä datamäärä on moninkertainen ihmismielen tuottamaan. Datan pohjalta on vikkelämpää löytää kentän fysiikkabugit ja pelisuunnittelun tasapaino-ongelmat.
Myös pelimaailmassa kilpapelaajat pystyvät paremmin analysoimaan, millainen sijoittuminen ja hyökkäystaktiikka de_dustissa todella toimii tai mitä herojen päivitys tarkoittaa Dotan tasapainon suhteen. MuZero vaatii taakseen konefarmin, mutta siitä kehitetty kevyempi versio voisi toimia yhden videopelin todellisuudessa. Monte Carlo -puuhaku on jo käytössä monen pelin tekoälyssä, sillä itse idea on vanha.
Samalla tekoälyn tehtäväksi saattaa nousta viihdyttävän häviämisen sijaan viihdyttävä voittaminen. Sen sijaan, että moninpelissä muut tiimiläiset olisivat idiootteja apinoita, kohta saakin olla koko pelissä ainoa sellainen. Sinä päivänä lause: ”Olen aika haka yksinpelissä” kuulostaa ensimmäistä kertaa nettipelien historiassa itsekehulta.
Valitettavasti visiot ovat visioita. Todellisuudessa MuZero, yksi maailman kovimmista Atari 2600 -pelaajista, on nyt valjastettu kehittämään Youtube-videoiden pakkausalgoritmia.